智东西
作者 | 李水青
编辑 | 云鹏
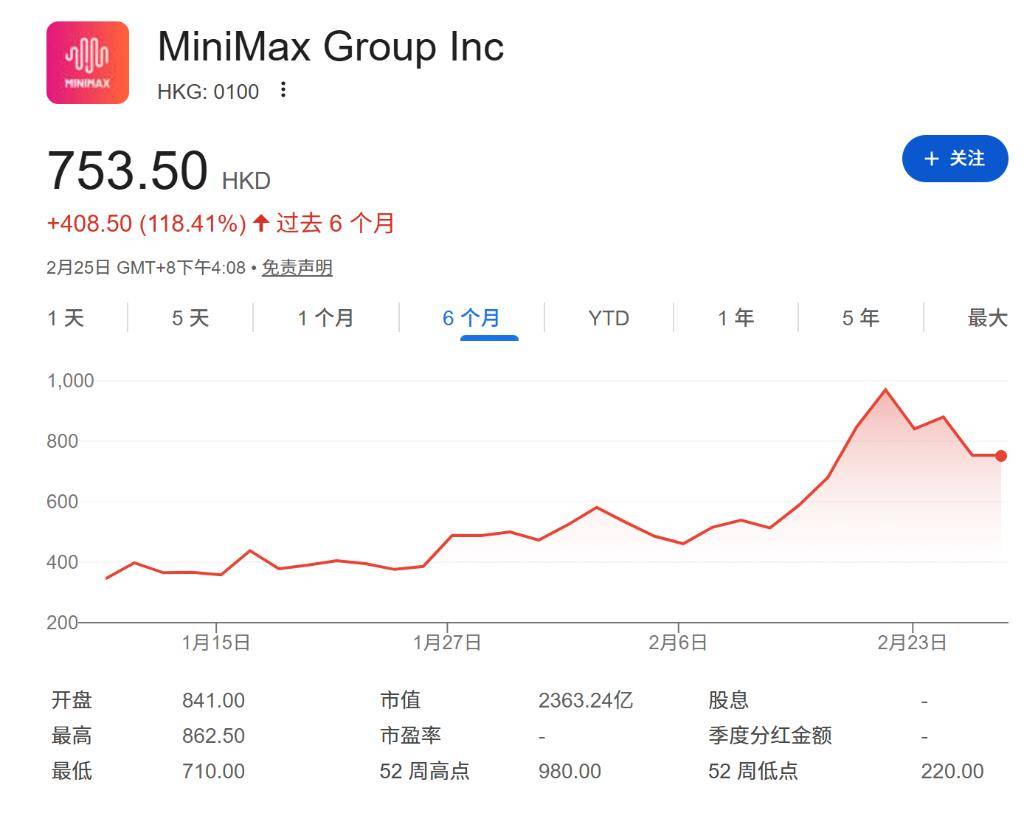
智东西2月25日报道,今日,阿里推出马年首批新模型——Qwen3.5中型模型系列,包括推出Qwen3.5-122B-A10B、Qwen3.5-35B-A3B、Qwen3.5-27B(Dense)三款开源模型,同时Qwen3.5-Flash(Qwen3.5-35B-A3B生产版本)API已上线阿里云百炼。
Qwen3.5最新三款中型模型在指令遵循、研究生级推理、哈佛-MIT数学竞赛级数学、多语言知识、智能体工具使用等
12项能力测评中,在通用推理、数学、智能体、多模态等多个方面,整体表现可与GPT-5 mini、Claude Sonnet 4.5等国际一流模型相媲美。
▲Qwen3.5中型模型系列测评情况
模型一经发布在开发者圈引起关注。多位开发者称这些模型尺寸是本地推理的绝佳选择,赞叹其“更小模型实现更强性能”,甚至有人称Qwen3.5-35B-A3B有望将其每月花费从2000欧元(购买Gemini服务)降至50欧元,大大节省成本。
▲社交平台X上的网友评论
具体来看,其中最受关注的Qwen3.5-35B-A3B,性能已超越参数规模大数倍的Qwen3-235B-A22B-2507和Qwen3-VL-235B-A22B。正如一位海外网友所说:“架构+数据质量>原始参数。我一年来一直这么说。”
▲社交平台X上的网友评论
Qwen3.5-122B-A10B和Qwen3.5-27B进一步缩小了中型模型与前沿模型之间的差距,尤其是在复杂智能体场景中表现突出。Qwen3.5-Flash是与35B-A3B版本一致的托管生产版本,主打以较快速度提供强性能,每百万Token价格低至0.2元,默认支持1M超长上下文长度,满足长文档与复杂任务处理需求。
目前,Qwen Chat上的模型均已更新为Qwen3.5系列,最新四款中型模型也已上线。智东西第一时间对这三款开源模型进行了初步体验,发现这三款中型模型已能满足多种日常的多模态理解、知识解答、视觉编程等任务,达到匹敌Qwen3-235B-A22B-2507的效果,不过在SVG卡通场景绘制等场景仍有提升空间。
▲四款新模型已上线Qwen Chat
持续迭代的产品力有望让阿里千问占据更大市场。近期,国际市场调研机构沙利文报告显示,2025年下半年,中国企业级大模型日均调用量千问(Qwen)占比32.1%位列第一,相较上半年的17.7%几乎翻倍,相比字节豆包(21.3%)、DeepSeek(18.4%)领先优势扩大。
Hugging Face地址:
https://huggingface.co/collections/Qwen/qwen35
魔搭社区地址:
https://modelscope.cn/collections/Qwen/Qwen35
体验地址:
https://chat.qwen.ai/
一、实测多模态与知识能力出色,小体格编程强,SVG生成待提升
在智东西的初步体验中,三款模型在多模态理解和知识能力上都效果不错。
比如当我上传一张“公鸡根雕”的图片,三款模型都能够准确识别其为根雕艺术品,能够根据颜色和纹理准确识别材料为“崖柏”,能结合中国传统文化解读这一物件的意义,甚至能基于材质、工艺水平、尺寸大小等因素进行价格评估,评估结果基本符合这一领域的专业水平,令人很惊喜。
如下图所示,Qwen3.5-122B-A10B和Qwen3.5-35B-A3B的输出答案都基本接近事实,对“这是什么物件,用的什么原材料,有什么寓意,可能值多少钱?”四个问题进行了准确的理解作答。
▲Qwen3.5-122B-A10B生成的答案
Qwen3.5-27B的输出内容在形式上更加别出心裁,不仅对几个问题进行了准确回答,还通过图表、格式变化等方式,让内容呈现更加重点分明,并最终给出了“5000-15000元”较为直接可参考的估价,体现了其“工程实用度高”的特点。
▲Qwen3.5-27B生成的答案
而后智东西着重考察了Qwen3.5-27B(Dense)的编程能力,让其生成一个“虚拟助手个人智能体OpenQwen的官方主页”,并提出“该助手可辅助编程、办公、购物等各类事务。生成高质量图片作为网站素材,包含智能体头像及功能使用场景演示”等特征。
如下图所示,Qwen3.5-27B能够比较完整地生成这一网站的页面,逻辑上基本与提示词描述契合,展现其以较小参数规模实现了较强视觉编程能力的特征。不过相比Qwen3.5-397B-A17B的视觉编程能力,Qwen3.5-27B在视觉元素丰富程度、交互性等方面仍有一些差距。
▲Qwen3.5-27B生成的代码预览情况(部分)
▲Qwen3.5-397B-A17B生成的代码预览情况
而在SVG卡通场景绘制的场景中,智东西要求三款模型输出“阳光沙滩”的SVG卡通图,对尺寸、主题、元素、风格和细节要求具体,三款模型在复杂约束下输出的SVG基本结构清晰,但太阳、海浪、遮阳伞、椰子树等物体的贴近程度仍表现不足。
▲提示词
Qwen3.5-122B-A10B生成的SVG相对更加准确,椰子树下的阴影更符合物理规律,画面的饱和度更加高。
▲Qwen3.5-122B-A10B生成的SVG
▲Qwen3.5-35B-A3B生成的SVG
▲Qwen3.5-27B生成的SVG
二、35B模型超235B,开发者喜迎降本,催更1B小版本
2月16日,阿里正式推出原生视觉语言模型Qwen3.5,Qwen3.5系列的第一款模型Qwen3.5-397B-A17B首次以开源权重形式亮相,该模型在推理、编程、智能体能力与多模态理解等全方位基准评估中领先,引起产业关注。
仅仅一周多之后,阿里发布了Qwen3.5系列几款中型模型,进一步在海内外引起开发者的高热讨论。
其中最受关注的当属拥有350亿参数的Qwen3.5-35B-A3B。多位网友称Qwen3.5-35B-A3B击败2350亿参数的Qwen3-235B-A22B-2507是“重点”、“大新闻”。
有网友称:“更小的模型在更便宜的硬件上运行速度更快,同时还能达到甚至超越大型模型的性能——这才是AI真正的民主化。”还有网友分享:“我现在在一个项目上每月要花2000欧元购买Gemini服务,如果这是真的,那费用就降到每月50欧元了。”
▲社交平台X上的网友评论
一位开发者分享了其部署Qwen3.5-35B-A3B的情况,称模型可以跑在16GB的显存机器上,处理32k上下文时,每秒处理数能达到60-70个任务;但他也提到,模型吞token的速度惊人,一个短谜题就用了大约6k token,但最终答案是正确的。
▲社交平台X上的网友评论
Qwen3.5-27B的模型参数更小,也做到了“小规模强性能”。一位网友称:“Qwen3.5-27B型号的得分为何如此之高?GGUF版本何时发布?”另一位网友也称:“这次发布太棒了!我对27B参数模型特别感兴趣,不过以后你们能不能把GGUF模型也和主版本一起发布?这样用户就能更快地用上这个模型。”
▲社交平台X上的网友评论
也有网友开启了催更模式。有网友称:“有计划发布小型模型吗?比如1B/3B/7B?”,也有网友喊话:“我希望未来几周内也能推出2-4B参数的型号,Qwen3-4B-2507或许是迄今为止性能与体积比最高的型号,我希望你们能延续这一传统。”
▲社交平台X上的网友评论
不过也有网友表达了更高的期待:“我真搞不懂为什么这张图表(测评图表)里没有Claude Sonnet 4.6和Opus 4.5这两款在SWE认证评分中分别高达79.6分和80.6分的机型。”
▲社交平台X上的网友评论
三、基准测试:122B大而全,35B强在智能体,27B工程实用度高
看完实际体验,我们再回过头来看看具体的测评成绩。从这三款模型的定位来看:
Qwen3.5-122B-A10B是一个相对大而全的模型,综合能力最强,相对适合多模态、视频、多语言场景;
Qwen3.5-35B-A3B的优势集中在智能体深度能力,适用于智能体规划、深度推理、任务调度,空间智能能力强;
Qwen3.5-27B(Dense)主打轻量化部署,工程实用度高,交互、编程、长文本、数学拔尖。
在知识维度,Qwen3.5-122B-A10B在专业领域知识与推理(MMLU-Pro)、多语言与多领域知识(MMLU-Redux)、研究生级知识与推理(SuperGPQA)三项取得最高分。在指令跟随、长上下文处理和STEM推理三大维度,Qwen3.5全系列都取得领先的成绩。
在编程能力上,Qwen3.5-27B在SWE-bench Verified(真实软件工程问题解决能力)中取得最高分,Qwen3.5-122B-A10B在Terminal Bench 2(终端环境下的代码执行与调试能力)和 FullStackBench en(英文全栈开发能力)中表现最佳。
在通用智能体维度,Qwen3.5系列呈“梯队式优势”,在BFCL-V4(通用智能体工具使用能力)、TAU2-Bench(智能体任务执行与适配能力)、DeepPlanning(智能体深度规划与逻辑推演能力)等多项测评中取得最佳成绩。在搜索智能体维度,Qwen3.5-122B-A10B主导英文/中文浏览检索,Qwen3.5-27B包揽复杂推理与综合搜索最高分。
在多语言能力维度,Qwen3.5-122B-A10B表现尤为突出。在多模态能力维度,其在通用VQA领域也表现强势,拿下RealWorldQA(真实世界场景下的视觉问答能力)、MMStar(多模态综合理解与推理能力)等四项最高分;Qwen3.5-27B在HallusionBench(多模态幻觉抑制与事实一致性能力)、CharXiv(RQ)(学术文档的理解与检索能力)等评测中表现最佳。
在空间智能方面,Qwen3.5系列实现全维度领跑。在视频理解方面,Qwen3.5-122B-A10B成为本次测评的绝对领跑者,包揽带字幕的视频多模态理解能力、视频与语言结合的跨模态理解能力等6项单项最高分。
聚焦视觉智能体与专业视觉能力,Qwen3.5系列垄断视觉智能体与医疗视觉核心能力:在8项测评中,Qwen3.5系列包揽了6项最高分,仅在桌面系统交互(OSWorld-Verified)上落后于GPT-5-mini,整体视觉智能体与医疗视觉能力领先。
四、对比Qwen3,解读Qwen3.5五大技术升级
按照千问研发团队的思路,智能进步的关键,从来不是堆参数,而是更优架构+更高质量数据+强化学习(RL)的有效协同。
相比于阿里上一代旗舰模型Qwen3,Qwen3.5具有以下增强功能:
统一视觉语言基础:在多模态标记上进行早期融合训练,实现了与Qwen3的跨代对等,并在推理、编码、Agent和视觉理解基准测试中优于Qwen3-VL模型。
高效混合架构:门控Delta网络与稀疏混合专家相结合,可实现高吞吐量推理,同时最大限度地减少延迟和成本开销。
可扩展的强化学习泛化:将强化学习扩展到百万智能体环境,并逐步增加任务分布的复杂性,以实现强大的现实世界适应性。
全球语言覆盖范围:扩展支持201种语言和方言,实现包容性的全球部署,并具备细致入微的文化和区域理解。
下一代训练基础设施:与仅文本训练相比,多模态训练效率接近100%,异步RL框架支持大规模代理支架和环境编排。
结语:企业级大模型市场头部效应初显,产品迭代速度是关键
通过此次发布Qwen3.5中型模型系列,阿里试图以“更优架构+更高质量数据+强化学习”,验证了“规模法则”之外的另一条进化路径。
三款模型的发布时间距离Qwen3.5-397B-A17B仅一周,分别切入多模态、智能体深度推理与轻量化部署三大场景,在开发者圈引发了模型成本热议,也快速补齐了其产品矩阵。
从市场格局看,Qwen系列在国内企业级市场的日均调用量份额从17.7%跃升至32.1%,进一步拉大领先优势。此次发布通过分层产品矩阵,有望进一步巩固其在企业级市场的头部地位。


 京公网安备 11011402013531号
京公网安备 11011402013531号