本文发表于《指挥信息系统与技术》2025年第6期
作者:金欣,周中元
引用格式:金欣,周中元 . 人类智能与大模型智能对比及指挥信息系统演进方向[J]. 指挥信息系统与技术,2025,16(6): 1-10.
摘要
为推动指挥信息系统智能化发展,需深刻理解智能化技术的本质。首先,简要概述了指挥信息系统智能化发展历程,围绕人类智能与当前大语言模型智能异同这一热点议题展开探讨,指出二者在泛化性、涌现性和意识特征等方面表现相近,但智能内核存在本质差异,是“精致的统计模仿”与“深邃的因果理解”的相遇;然后,进一步探讨了机器智能未来可能与人类智能媲美的几条关键发展路径,包括神经符号人工智能(AI)、具身通用人工智能(AGI)和脑启发计算等方向,为下一步指挥信息系统智能化发展提供了思路。
0
引言
从基于符号知识的指挥决策支持专家系统,到基于仿真模拟的计划推演、基于深度学习的图文情报处理和基于强化学习的战术智能决策,再到基于大语言模型的军事智能问答和军用文书生成等,指挥信息系统智能化发展一直遵循通用领域人工智能技术的发展趋势。解析人工智能未来的发展趋势是研究指挥信息系统智能化发展方向的重要议题。
当大语言模型流畅地生成文章或解答难题时,其表现出的能力能与人类相媲美。近期,从学术界到工业界,一个被广泛热议的话题是大语言模型越来越接近人类,甚至可能具备一定意识。本文将从相近之处、本质差异与未来路径3个维度深入剖析这一议题,并就未来指挥信息系统智能化发展潜在技术路径提出建议。
1
发展历程
指挥信息系统智能化发展大致涵盖了符号知识、仿真模拟、深度学习、强化学习和大型语言模型5条技术路线。
1.1 从专家系统到知识图谱——符号知识路线
将指挥人员的经验知识“教”给机器,使机器能够按照人的方式完成任务,是人工智能的符号主义流派,也是指挥信息系统智能化发展中最早且最朴素的理念。从早期专家系统到近期知识图谱,这条路线上的探索一直在持续。
早期专家系统的代表性工作是美国国防高级研究计划局(DARPA)推动的未来指挥所(CPOF)计划。1997—2003年,DARPA先后发起了高性能知识库(HPKB)和快速知识形成(RKF)2个项目,旨在支持各个军事领域的专家快速构建包含百万条公理的超大规模知识库,并使其能够面向实际军事应用问题提供解答。
2012年,谷歌发布了包含570亿实体的大规模知识图谱,掀起了知识工程的新热潮。在此背景下,DARPA启动了机器常识(MCS)、开放世界新事物的人工智能(AI)和学习科学(SAIL-ON)、知识导向推理(KAIROS)、世界建模者(World Modelers)、大机制(Big Mechanism)、因果探索(Causal Exploration)、不同来源主动阐释(AIDA)与数据驱动的模型发现(D3M)等一系列项目,在新的知识工程道路上持续推进探索。
目前:知识处理正从静态实体类知识向动态事件类知识转变,从基础三元组表示向连续向量和复杂高阶表示发展,从关系建模向复杂路径建模延伸;知识推理也正从确定性规则推理向不确定性概率推断方向发展,致力于解决大规模、跨领域和开放式知识处理中的计算效率、智能推荐与常识推理等问题。
1.2 从“深绿”到数字孪生战场——仿真模拟路线
20世纪80至90年代,计算机仿真技术趋于成熟并开始在各个领域广泛应用。在作战指挥领域,计算机仿真主要用于模拟推演作战计划的执行过程,分析计划中存在的漏洞和冲突。受到当时计算处理能力限制,大规模且大批量的计划推演尚无法实现。1997年,IBM公司研发的“深蓝”(Deep Blue)计算机打败了世界冠军卡斯帕罗夫。在强大算力驱动下,高性能计划推演成为可能。
受“深蓝”计算机影响,DARPA于2007年启动了“深绿”(Deep Green)计划,旨在将仿真技术嵌入指挥控制系统,提高指挥员临机决策的速度与质量,将美军战术级作战任务规划周期缩短75%。虽然该计划因主管领导更迭和经费削减等原因于2011年暂停,但其思想对后续美军作战指挥系统智能化发展产生了深远影响。
2012年,美国航空航天局(NASA)发布了建模、仿真、信息技术和处理路线图,数字孪生技术开始飞速发展。2014年美军提出数字战场概念,并基于这一概念进行了相应的系统建设和包括“沙漠铁锤”、“草原勇士”、“集中派遣”和“勇士聚焦”等在内的一系列作战试验。通过伊拉克战争和阿富汗战争等实战验证,构建了美国陆军旅及旅以下战斗指挥系统(FBCB2)等一系列数字战场信息系统。
数字战场将利用人工智能实现蓝军自主对抗、虚实空间迭代演进和作战规则孪生学习。此外,数字战场具备虚实融合的平行推演与体系验证能力,可满足作战指挥和日常训练对作战推演真实性、时效性、精准度与对抗性等的需求。
2009—2014年,DARPA先后启动了洞察(Insight)、可视化数据分析(XDATA)、深度学习(Deep Learning)、文本深度挖掘与过滤(DEFT)和高级机器学习概率编程(PPAML)等大量基础技术研究项目,探索发展相关技术。从文本、图像、声音、视频和传感器等不同类型多源数据中,自主获取并处理信息,通过提取关键特征挖掘信息的关联关系。
2017年,美国国防部成立算法战跨职能小组(AWCFT)并启动了Maven项目,通过深度学习和计算机视觉算法对全动态视频图像中的目标进行监测、分类和跟踪,将大量数据快速转化为作战情报并形成观点,帮助指挥官快速制定决策。2024年,美军对伊拉克和叙利亚境内超过85个目标进行空袭,美国国防部官员证实使用了Maven项目中的技术。
1.4 从智能空战到智能兵棋——强化学习路线
2016年,DeepMind公司研发的围棋计算机AlphaGo,战胜了人类围棋冠军李世石。这件事带来的启示是,通过强化学习技术,计算机可以在虚拟世界中以人类速度的千万倍速,进行探索试错模式的学习,并且在某个领域超过人类最高水平。
同年,美国辛辛那提大学开发的人工智能系统“阿尔法”(Alpha AI),在模拟空战中100%击败了经验丰富的美国退役空军上校。“阿尔法”在空中格斗中快速协调战术计划,整个过程不到1ms,速度比人类飞行员快了250倍。“阿尔法”可同时躲避数十枚导弹并对多目标进行攻击,还能协调队友,同时观察学习敌人战术。
2019年,DARPA启动空战演进(ACE)项目,将自主空中格斗应用至更复杂且异构的战役级对抗场景,并多次举办人机空中格斗挑战赛推进技术发展。2024年5月,美国空军部长乘坐的F-16D改装飞机,在没有任何操控介入的状态下,通过AI系统完成了自主起飞、巡航、目标搜索和攻击,战胜了另一架人类飞行员操控的F-16战斗机。这标志着智能博弈在战斗级控制领域已经走向了实用化。
时至今日,强化学习技术已成功应用于智能空战和智能兵棋等领域。基于探索试错强化学习作为一种积累经验知识的普适性方法,在生成式AI技术中也获得了新的发展,从虚拟世界中的探索试错到在人类反馈中的探索试错,均展示出旺盛的生命力。
1.5 从内容生成到工具调度——大语言模型路线
2023年初以来,以ChatGPT为代表的大语言模型技术,引发了前所未有的轰动效应,获得了美军的密切关注。美军方核心机构充分肯定了生成式人工智能在构建美国未来数字战场中的巨大潜力,并随后积极开展大语言模型军事应用探索与实践。
2023年4月,Palantir公司发布国防人工智能平台(AIP),实现了自然语言驱动的新型指挥作业模式。其中,大语言模型充当翻译官和调度员的角色,可将指挥员自然语言表达的意图翻译成机器语言,自动组织调度专用模型快速完成指挥作业。2023年8月,美国国防部宣布成立生成式人工智能工作组Lima,重点推进大型语言模型技术研究。
从2023年到2024年,美军各军兵种先后推出了Amelia、COA-GPT与NIPRGPT等大语言模型应用2025年,美国国防部先后授权Scale AI、Anduril与微软合同研发雷霆熔炉系统,授予XAI、Anthropic与谷歌合同研发智能体工作流,并推出安全人工智能平台GenAI.mil及政府版Gemini,全面覆盖作战指挥和建设管理域。
大语言模型在指挥信息系统中的应用包括指控领域知识问答、军用文书写作、多模态情报处理和方案计划生成等,强大的内容生成能力可显著提高指挥作业效率。同时大语言模型可作为操作系统,提供自然人机交互引擎,准确理解用户意图,组织专业小模型完成传统需大量人工操作且需使用多个工具的复杂任务。
上述技术路线在情报处理、行动规划和管理控制等领域均取得了广泛应用。然而,在态势研判和决策制定等高层认知域,也是指挥控制的核心领域,由于缺少大量标注的数据积累、高层决策经验知识难以抽象提炼和复杂作用机理难以仿真建模等原因,发展较为缓慢。大语言模型展现出类人的智能,尤其是对自然语言文字的精准理解和生成能力,让人们看到了希望。那么,这种类人的智能与真正的人类智能有哪些异同之处呢?
2
相近之处
大语言模型的成功,在于它高效地模拟了人类智能表现出来的一系列能力特征,包括泛化性、涌现性和意识特征。
2.1 泛化:从模拟知识学习到模拟记忆比对和直觉构建
泛化(generalization)通常定义为将知识或技能从特定实例或样例迁移到新场景的过程,可理解为一种迁移学习能力,即将从过往经验中学习到的表示、知识与策略应用于新领域的能力,通俗理解就是举一反三和活学活用的能力。泛化的本质不是记忆搜索,而是理解应用。科弗说:泛化始于记忆终止之处。只有当系统的记忆能力受到限制时,模型才能对新数据实现泛化。当模型真正具备泛化能力时,便不再是一个冰冷的数据库,而是开始像一个真正会思考的大脑。
在认知科学中,人类的泛化通常包括3个主要过程:第1步是抽象,即将具体实例抽象为某种高度凝练的知识表征,包括类别与概念,以及规则或关系;在此基础上,当遇到新的实例时,如果差别不大,将已习得的知识表征套用到新的实例上,即第2步扩展;如果差别较大,但仍属于已习得的知识范畴,则进行第3步类比,即对已有的知识表征进行调整或适配,以适应新的场景。
2025年,文献将AI的泛化方法分为以下3种类型:
1)知识驱动的方法。早期AI试图成为一个完美的逻辑系统,通过知识来学习和推理。例如,它能从“A是B的父亲,B是C的父亲”推导出“A是C的祖父”。人类的知识可表征为机器能够理解的形式,例如类别和概念表征为各种符号、属性、原型、样例或概率分布,规则或关系被表征为参数化或非参数化形式的函数或图。这种定义清晰的知识表征具有设计可解释性,易于理解与修改,且泛化行为通常与人的预期一致,在相关特征及关系可被语言描述这类高层认知领域尤为适用。然而,其优点也正是其局限,它无法应用于难以形式化建模的领域,无法应对真实世界的模糊和不确定性,泛化能力十分有限。
2)基于实例的方法。AI并不显式地学习某种概念,而是通过比较新实例与已知事物样例的相似度,对新实例进行分类,如K近邻和基于案例推理等。该方法如同一个不囿于教条的人,每次均借助过往经验进行比较,因而能灵活泛化并扩展至新的实例和场景。记忆即知识,故不存在学新忘旧这种灾难性遗忘问题。但该方法极度依赖相似性,合适的表征是泛化的关键,直接影响模型在不同数据集与任务间捕捉模式的能力,难以进行深入推理。此外,若要存储海量实例,需要强大的记忆力支撑。
3)基于统计的方法。该方法基于观测到的实例(即训练数据),提取适用于整个群体的模型(即潜在分布)。包括深度学习在内的许多现代机器学习方法,均以统计泛化为目标。这种方法几乎没有搜寻知识和记忆的推理过程,能直接给出判断,类似于人类长期实践形成的直觉。凭借在大规模数据集上的优越性能,该方法现已成为机器学习的主流分支。它具有强大的通用近似能力,推理大规模数据集的推理准确性与效率较高。但其局限也与人类直觉相似:对于训练数据统计分布之外的数据集 “直觉”常常失效。并且,“直觉”如同黑箱,很难令人信服。更重要的是,该方法对数据规模和质量要求极高。当下流行的大语言模型根植于统计学习原理,本质上是通过统计和分析海量文本,训练出的语言概率大师。借助反向传播和梯度下降等算法,模型在最小化预测损失过程中,能够捕捉到数据中最具判别性的稳健特征表示。这种对底层特征的学习,是其强大泛化能力的根本来源。
2.2 涌现:大语言模型表现出类人的“顿悟”或“开窍”
涌现(emergence)现象最初在物理复杂系统中被发现。例如,一个复杂系统由很多微小、相互作用且看似无序的个体构成,这些个体数量达到一定程度后,会突然在某个临界点引发相变,在宏观层面上展现出微观个体无法解释的特殊现象,即展现出某种整体的规律性,这就是涌现现象。
这种现象在生活中比比皆是。例如,当大量水分子在外界温度条件的变化下相互作用时,宏观上会形成规律且对称的雪花;当沙子聚集成沙漠时,会形成类似波浪的棱线,而沙堆在某个临界点又会突然发生雪崩式坍塌;当候鸟聚集成群时,会自发地排列成特定图案飞行。
人类在学习过程中也会出现涌现特性,常称为“顿悟”或“开窍”。随着阅历增长,人们会发现很多事物规律间存在某种隐藏的关联性,从而一窍通则百窍通。而令人惊奇的是,人们在大语言模型上似乎也看到了这种涌现特性。在当模型的参数超过某个临界值时,性能显著提高,能力突然涌现。而这种相变是无法通过小模型的试验观察到的。这种涌现特性突出表现在2个方面:1)上下文学习(In Context Learning),也称为少样本提示(Few-Shot prompt),即用户给出几个例子,大语言模型无需调整模型参数,就能够处理好任务;2)思维链(CoT),即用户提供推导步骤,大语言模型就能完成复杂推理任务。
大语言模型的涌现能力来源于以下5个方面:
1)深层模式学习:大语言模型凭借庞大的参数网络,能捕捉到极其细微且高阶的复杂关联,学习到物理定律、社会规则和人类情感的复杂模式。
2)知识压缩泛化:大语言模型在某种意义上是对海量数据进行的极致压缩。这种对世界知识的深度表征,是其进行常识推理和遵循复杂指令的基础。
3)Transformer架构:特别是其自注意力机制,允许模型高效地捕捉长距离依赖关系。这为理解复杂的上下文和生成逻辑连贯的内容提供了结构上的保障。
4)过参数化与非线性映射:当参数远超训练样本数,反而有助于提升模型泛化能力,能够拟合更加复杂且抽象的函数,在不同概念间建立小模型难以实现的联系。
5)性能激发方式:通过少样本提示、多数投票以及使用更复杂和推理步骤更多的样例作为提示等方式,可有效激发模型的推理能力,甚至超过缩放法则预测的效果。
2.3 意识:大语言模型在对话中表现出类人的“意识”体验
大语言模型能够令人信服地模仿人类对话,这让很多人相信与他们互动的系统是有意识的。曾有150万用户在线参与了大语言模型的图灵测试,结果表明,被测试者分辨对面聊天的是AI还是人类的正确率平均为68%。并且,该项研究可能并未显示出大语言模型的全部能力。通过优化训练方法,可以弥补一些训练偏差,从而进一步降低人类辨别的正确率。很大程度上,大语言模型已非常接近甚至通过了图灵测试。
2023年8月,文献基于现有的各种意识理论提出了14条评判指标,并对GPT-4等主流大语言模型进行了测试。结果表明,这些模型部分符合其中若干指标,但无法满足所有指标。因此,尽管目前尚无具备意识的AI系统,但如果上述评估准则成立,有意识的AI系统可以在近期得以建立。
在最新一期播客节目中,Hinton谈到AI是否有主观体验时表示:我相信它们有。只是它们自己不知道,因为它们的自我认知来源于我们,而我们自己对意识的理解就是错的。他举例说,如果一个能看能说的机器人因为棱镜折射看错了物体位置,事后纠正时说“我有过一个错误的主观体验”,那它其实就在使用和我们相同的意识概念。换句话说,如果AI开始谈论主观体验,那也许说明它真的在体验——只是用我们的语言在描述。Hinton借此提醒大家:当AI比我们聪明得多时,最危险的不是它反叛,而是它会“说服”。它会让那个要拔插头的人真心认为拔插头是个糟糕的决定。
Mustafa认为,以下4项能力会使AI有意识的说法越来越有说服力:1)连贯且一致的记忆,不仅来自训练数据,更源于与世界互动积累的真实亲身经历;2)富有同理心的沟通,当前AI这此方面已经非常接近人类水平;3)提及并运用“我”的主观体验,AI不再是一问一答的机器,它能将作为AI的感受融入持续的对话流中;4)接入多模态信息,AI将能接入视频和音频,持续观察世界,并感觉自己成为对话的一部分。
3
核心差异
在人类智能与大模型智能表面的相似性之下,是两者智能运作的根本差异:人类智能中占据主导的是因果模型,是在真正理解事物概念和运行机理基础上的融会贯通,是在具身体验驱动下的意识行为;大语言模型智能基于统计学原理,借助大量数据统计达到类似人类的智能水平,在角色扮演过程中产生拟人的意识行为。
3.1 泛化:因果推理 vs. 统计插值
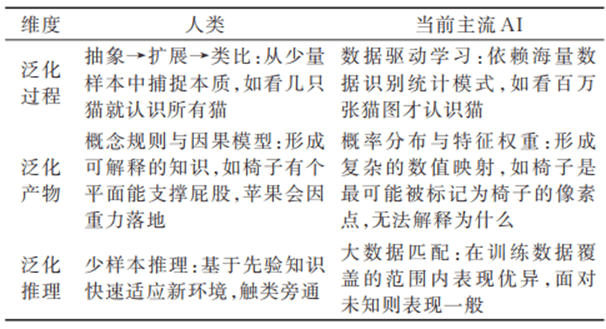
人类的泛化,走的是抽象的路。人类擅长从少量样例中抽象出通用特征,构建通用概念与规则,实现组合性泛化与常识推理,并能鲁棒地适应噪声与分布偏移。其核心原因在于通过生物进化和经验积累,人类可在多个层级获取强大的常识,这些常识刻画了自然界的物理规律与人类交互中的行为模式,且通常由因果推理驱动。早期知识驱动型AI旨在模拟人类的泛化原理,但它从复杂实例中抽取概念的能力,与人类相差甚远。
当前主流AI的泛化,走的是统计的路。统计学习是在数据空间中进行数学插值,学到的是模式而非概念,依赖相关性而非因果推理,所以对数据分布外的情况能力极差。其优势主要体现在处理大规模数据、提升推理效率与准确性、应对高数据复杂度,以及实现逼近普适性等方面。但当前主流AI需要成千上万,甚至数百万个数据样本喂养,才能勉强记住模式,难以实现并超越训练分布的泛化,也无法有效进行抽象。张钹院士等学者指出,这类缺乏可解释性和因果性的模型,难以实现真正的安全与可靠。人类与当前主流AI的泛化特性对比如表1所示。
表1 人类与当前主流AI的泛化特性对比
与人类智能相比,号称阅遍人类记载知识的大语言模型在静态知识和统计分析方面确实更加强大,但在动态知识、概念理解和情绪价值等其他方面,其智能水平仍远不及人类,甚至还不如孩童。例如,在察言观色和随机应变等方面,大语言模型尚难企及。这种差距可能与学习方式不同有关:人类自出生开始接触世界,每时每刻都在学习,学习方式也丰富多样,有与大语言模型一样的读书学习,但更多的是跟大人模仿学习和在实践中摔打学习。人类的基因印记也绝不是大型语言模型的初值可以类比的,正如羚羊出生几分钟后就能在稀树大草原上奔跑,这种与生俱来的能力连人类也望尘莫及。
3.2 涌现:融会贯通 vs. 统计表象
涌现原本是一种物理现象,而当我们提到大语言模型的涌现特性时,常将其与人类的某种能力类比。人类在学习过程中会出现一窍通则百窍通的现象,又称“顿悟”。本文认为这建立在人类对各领域知识融会贯通的基础上,源于对事物本质规律间隐藏关联的真正发现,即底层逻辑揭示。这种关联是有意义的,可以很好地指导实践。一旦人们理解了这些底层逻辑,就不会再被纷繁的表象迷惑。
大语言模型的涌现是一个复杂的现象,受多种因素共同影响,具有不确定性。一个模型在特定任务上是否会出现涌现现象,取决于任务的性质、模型的结构和训练的方式等因素。一个模型可能在一个任务上呈现线性增长,而在另一个任务上表现出涌现,且具体在何种规模下会出现涌现也是不可预测的。上下文学习和思维链是否一定属于涌现现象,也并非绝对。只能说在大多数情况下,确实仅在大语言模型中才会出现。
此外,多项研究指出,人们在很多任务上看到的大语言模型涌现现象,也许只是其他原因造成的一种表象,主要包括以下2个方面:
1)任务评价指标不够平滑:在训练过程中,大型语言模型输出的结果常是逐渐接近标准答案的。但如果评价指标要求很严格,要求一字不错才算对,就会在某个时刻突然看到涌现现象。但如果将评价指标设计得更精细些,例如给出与标准答案相似度的评分,就会发现涌现现象消失。
2)复杂多步任务的成功率叠加:前面提到过,展现出涌现现象的常是由多个子任务构成的复杂任务。假设某个任务有5个子任务,随着模型规模线性增长,每个子任务性能从40%提升到60%,总任务性能却从1.1%提升到了7%,也就是说宏观上看到了涌现现象。
归根结底,涌现能力只是对一种现象的描述,而非模型某种真正的性质。大语言模型在一些任务上表现出的涌现特性,与人们在物理学系统中看到的有着完全不同的表象和成因。关于其出现原因的研究虽越来越多,但多数仍处于猜想阶段。张钹院士等专家提出,不应将涌现神秘化。在某些情况下,涌现可能只是人们对模型内部复杂机制认知不足的托词。人们看到了结果,却无法清晰解释过程,于是便用一个宏大的词汇来概括。
3.3 意识:具身体验 vs. 角色扮演
意识(conscious)至今仍是一个令人困惑的概念,没有公认的定义。什么是意识以及意识如何产生在科学界和哲学界仍然存在广泛争议。在2022年的一次访谈中,图灵奖得主Yann LeCun表示:意识是一个非常模糊的概念,一些哲学家、神经科学家和认知科学家认为这只是一种错觉(illusion),他非常认同这种观点。他还认为,意识是人们大脑存在局限的结果。由此可见,人类的意识至今仍是个未解之谜。
意识涉及哲学、心理学、神经科学和认知科学等多个领域,相关理论很多,包括信息整合理论(IIT)、循环处理理论(RPT)、意识即物质状态理论、协同客观还原理论(Orch OR)、全局工作空间理论(GWT)、高阶理论(HOT)、注意图式理论(AST)、预测处理理论(PP)、意识图灵机理论(CTM)以及能动性与具身化(AE)等。综合各种理论,人类意识主要具有3个方面特性。1)觉知性(awareness):指个体对外部环境刺激(如光、声和气味)和内部身心状态(如疼痛、饥饿和情绪)的感知能力。没有觉知,就没有意识体验。2)主观性(subjectivity):意识体验具有第一人称视角,每个人的体验是独特且私人的,无法被他人直接感知。3)自我意识(self-consciousness):指个体能够意识到“我”是体验的主体,能够反思自己的思想、情感和行为。由此可见,人类的意识是一种具身体验,是外在激励与内在思想交融产生的。
关于AI是否具有意识,AI巨头Yann LeCun认为,人类的智慧是多维度的,除了逻辑计算,人类还有情感、直觉、共情和自我意识。那么AI是否真的理解自己在做什么,还是说,它只是一个越来越精于模仿的超级复读机。
谷歌最近发布的一篇Nature论文,引起LeCun等不少业内人士的共鸣。论文指出,大语言模型表现出类人的现象,主要有2个:1)欺骗性,指有时候大语言模型会坚称自己知道某件事,但其实给出的答案是错误的;2)自我意识,指有时候它会使用“我”来叙述事情,甚至表现出生存本能。这2种现象都是因为它在扮演人类的角色,而不是真的在像人一样思考——因为大语言模型这样的回答看起来更具有可信度。
研究人员认为,大语言模型并没有在扮演某个特定的角色。相比之下,它们就像一个即兴戏剧演员,在对话中不断揣测并调整自己扮演的身份。得出这个结论,是因为研究人员和大语言模型玩了一个称为20个问题的游戏。游戏中,回答者心中默念一个答案,根据提问者不断提出的判断题,用是或否来描述这个答案,最终提问者猜测结果。例如答案是哆啦A梦,一系列问题可能为:是否是活的、是否是虚拟人物、是否是人类,等等。对应的答案即为:是、是、不是,等等。研究人员在玩这个游戏的过程中发现,大语言模型会根据用户的问题实时调整自己的答案。也就是说,无论用户最后猜出的回答是什么,大语言模型都会调整自己的答案,确保结果和前面用户提的所有问题一致,而非事先确定一个明确的答案供用户猜测。这表明大型语言模型不会通过扮演固定角色来实现自己的目标,其本质只是一系列角色的叠加,在对话中逐渐明确并尽力扮演好所需的角色。
4
未来路径
展望未来,若要跨越当前智能的鸿沟,达到指挥决策的智能顾问甚至领域问题专家的水平,现有的以大数据和大算力驱动的大语言模型范式已显疲态,尤其是大语言模型难以根除的幻觉现象和黑箱问题等,是作战指挥应用不得不直面的问题。其瓶颈在于缺乏对世界的深度理解和真正的推理能力。
国内学界的探索与国际前沿同步,正聚焦于几条更具根本性的突破路径,分别从智能的载体、架构和本源出发,旨在为机器注入灵魂。而这几条路径对指挥信息系统下一步该如何发展,也具有一定的启示和参考借鉴作用。
4.1 神经符号AI:融合“系统1”与“系统2”
诺贝尔经济学奖得主丹尼尔·卡尼曼将人类思维划分为系统1(即快思考,直觉式、并行且无需努力)和系统2(即慢思考,序列化、需意志力且可推理)。当前大语言模型本质上是极致的系统1,能流畅地生成文本,但缺乏逻辑链条的显式维护和验证,导致其容易产生事实错误(即幻觉)与逻辑谬误。
这种融合能从根本上解决大语言模型的幻觉问题,使其输出兼具流畅性、逻辑严密性、事实准确性和过程可解释性。它使AI的思维过程接近人类的理性思考——先直觉判断,再通过逻辑审慎验证。这对作战指挥这种高可靠性领域的AI应用至关重要。美军DARPA于2022年启动有保证的神经符号学习和推理(ANSR)项目,将符号推理与数据驱动的学习深度融合,开发基于证据的推理技术,实现可信且可解释的情报处理。
4.2 具身AGI:从“阅读”世界到“体验”世界
当前的大语言模型通过阅读人类留下的海量文本记录来学习,如同从未离开过书房的理论家,虽能娓娓道来,却无法理解实际的物理含义。具身通用人工智能(AGI)的核心在于将大语言模型的符号理解能力与机器人技术相结合,让AI拥有身体(如机器人),通过感官(即视觉、触觉和听觉等)与运动系统在物理世界或高保真仿真环境中进行实时互动与学习。一旦AI通过亲身“体验”构建起世界的内部模型,它将获得目前大语言模型缺失的真正常识。它无需被明确告知,就能推断出水往低处流和在冰上行走要小心等常识。这将是实现可靠、安全和能在复杂现实环境中自主行动的AGI的基石。
具身AGI的实现路径包括3种。1)多模态学习:将视觉、触觉和听觉等信息与语言指令对齐,形成统一的内部表征;2)仿真到真实:在高度拟真的物理仿真环境中进行大规模和低成本的安全训练,再将学到的技能迁移至实体机器人;3)世界模型构建:AI通过在环境中互动,自发地在其内部构建一个关于物理定律、社会规则和因果关系的预测模型。
虽然语言文字是作战指挥的核心载体,但指挥信息系统接入的信息类型是多模态的。系统要能够真正理解战场态势,需要综合文本、图像、视频、音频和航迹等多模态战场信息。前出战术编队的行动指挥,需要在真实且实时的对抗环境中获得反馈并生成指令。要让系统能够像人一样理解态势并生成决策建议,终需走上具身AGI这条路径。
4.3 脑启发计算:从结构到价值的深度对齐
这条路径更具前瞻性和根本性,它认为要创造真正的人类级乃至超人类级智能,最直接的蓝图可能就是人类大脑本身。该路径包含紧密相连的2个方面:1)脑启发计算:不仅是模仿神经元的简单连接(如深度学习),更是深入地借鉴生物大脑的结构和算法。例如,预测编码理论认为大脑是一个不断进行预测与验证的器官,它并非被动处理信号,而是主动生成对世界的预测,并将预测与感官输入的差异(即预测误差)作为学习信号。这种高效且节能的计算范式与当前AI的前向传播有本质不同;2)价值对齐:随着AI能力逼近甚至超越人类,确保其目标与人类价值观保持一致成为最严峻的挑战。价值对齐研究旨在开发技术,使高级AI能准确地理解并采纳和坚守人类复杂、多元且隐含的价值观。
在脑启发方面,需要研究如何将预测编码和全局工作空间理论等神经科学模型转化为可计算的神经网络架构,这可能突破当前AI在持续学习(即克服灾难性遗忘)、能效比和主动性方面的瓶颈;在价值对齐方面,需要解决对齐难题,即如何将复杂的、未经明确定义的人类价值观完整地“编码”给AI。技术路径包括逆强化学习(即从人类行为反推价值观)、可扩展监督(即让AI协助人类监督其自身)和机制可解释性等。
指挥员的思维模式,或许是指挥信息系统最难破译和模仿的对象。然而,知其所思并想其所想,方能谋其所谋并为其献策。要创造出能够真正高效服务于指挥人员的智能系统,可能终将走向这条路径。这条路径或许最终能触及意识、创造性和情感等最棘手的智能难题,展现出更强的环境适应能力和主动探索欲。然而,这也伴随着巨大的伦理和生存风险。成功结合脑启发计算与价值对齐,不仅是创造更强AI的关键,也可能是确保超级智能始终服务于指挥人员、避免失控的希望所在。
5
结束语
基础架构决定上层建筑。指挥信息系统智能化将如何发展,首先取决于人工智能这个基础本身。要让人工智能更好地服务于指挥人员的智能,首先要厘清这2种智能的异同点。本文聚焦这一热门议题展开论述,认为两者在泛化能力、涌现特性和意识行为上确实具有一定相似性,但其智能内核存在本质差异:人类智能是因果模型和具身体验的融会贯通,大语言模型智能则是基于统计规律的数据驱动。大语言模型与人类智能,实质上是“精致的统计模仿”与“深邃的因果理解”的相遇。
展望未来,人们期望指挥信息系统能够跨越当前智能的鸿沟,达到指挥决策的智能顾问甚至领域专家的水平,这需要更具根本性的突破路径。神经符号AI、具身AGI和脑启发计算,是目前国内学界探索与国际前沿同步开展的热点研究方向,值得重点关注。当前围绕这些技术方向与指挥信息系统结合的研究尚不多见,论文从原理上举例说明了它们在指挥信息系统中的应用前景和实现路径,对指挥信息系统智能化发展具有一定参考价值。
马政伟,肖元弼 .指挥信息系统软件研制中计划制定的思考[J]. 指挥信息系统与技术,2025,16(2):15-19.
孙煦云,姚伟. 面向智能化作战的大模型技术应用探索[J]. 指挥信息系统与技术,2024,15(6):28-35.
周烁,方正,蒋明鹏,等. 基于大型语言模型的中文短文本实体链接方法[J]. 指挥信息系统与技术,2024,15(6):41-47.
王鑫鹏,李晓冬. 基于大型语言模型的人机交互框架[J]. 指挥信息系统与技术,2024,15(6):74-78.
胡伟,姜晓夏,邵洲天,等. 大型语言模型智能体:机制和应用的综述[J]. 指挥信息系统与技术,2024,15(6):1-11.
毛少杰,易侃,闫晶晶,等. 软件定义指挥信息系统基本概念与原理[J]. 指挥信息系统与技术,2023,14(6):1-9.
万宜春,贾均强,张敏霞. 陆军部队指挥信息系统情报处理软件总体设计[J]. 指挥信息系统与技术,2023,14(3):65-69.
汪霜玲,李宇飞,黄凯鹏,等. 指挥信息系统智能化水平评估方法[J]. 指挥信息系统与技术,2022,13(5):55-59.
崔化超,戚志刚,王涛,等. 美航母编队指挥信息系统与作战指挥体制[J]. 指挥信息系统与技术,2022,13(4):8-13.
张慧,张骁雄,丁鲲,等. 美军智能数据情报KAIROS项目分析[J]. 指挥信息系统与技术, 2021, 12(1): 45-49.




 京公网安备 11011402013531号
京公网安备 11011402013531号